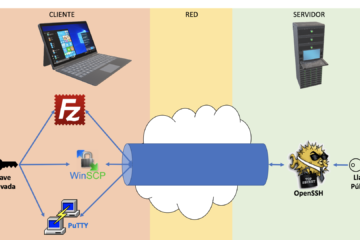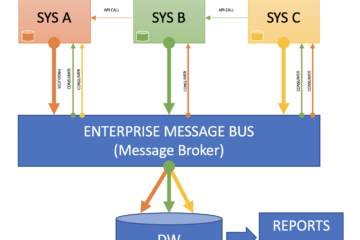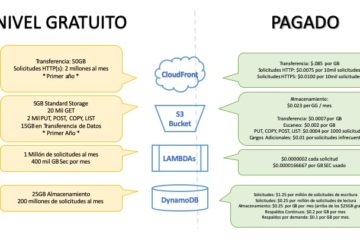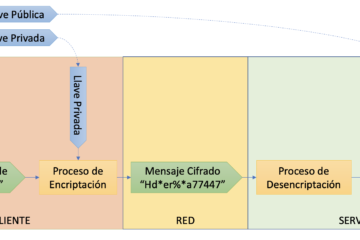
Ejemplo de llaves criptográficas
En nuestra publicación reciente y detallada sobre SFTP y llaves asimétricas discutimos la creación y utilización de llaves criptográficas para comuniación cifrada de punto a punto usando diversas herramientas, tales como PuTTY, PuTTYGen, WINSCP, FileZilla, OpenSSH. En este pequeño artículo les hablamos un poco de cómo lucen las llaves criptográficas.